Large Language Models (LLMs) are great at a multitude of tasks. Ask them to code, write a novella, generate an image or a video… you name…
Uncensoring Flux.1 Dev: Abliteration #

Large Language Models (LLMs) are great at a multitude of tasks. Ask them to code, write a novella, generate an image or a video… you name it, they deliver.
But LLMs are limited by boundaries. They simply will refuse to respond to prompts that are harmful and reply with responses such as “As an AI assistant, I cannot help you.” While this safety feature is crucial for preventing misuse, it limits the model’s flexibility and responsiveness.
In this article, we will explore ‘abliteration’, alongside some other methods, to remove the model’s built-in refusal mechanism.
Abliteration #
ablated + obliterated = abliterated.
To ablate is to erode a material away, generally in a targeted manner. In a medical context, this generally refers to precisely removing bad tissue.
To obliterate is to totally destroy/demolish.
It’s just wordplay to signify this particular orthogonalization methodology, applied towards generally the “abliteration” of the refusal feature.
Ablating the refusal to the point of obliteration. (at least, that’s the goal — in reality things will likely slip through the net)
This is just one source. There isn’t a formal definition or origin for abliteration, but it sets the premiere for what is the best-known technique to uncensor LLMs (unofficially).
Huh? But what does it do? And what is orthogonalization? #
Oh, right. Andy Arditi’s blog explains that the refusal behavior in LLMs is mediated by a specific direction in the model’s residual stream:
We find that refusal is mediated by a single direction in the residual stream: preventing the model from representing this direction hinders its ability to refuse requests, and artificially adding in this direction causes the model to refuse harmless requests.
In simple terms, orthogonalization refers to making sure different parts of a model (like its weight matrices or internal components) do not interfere with each other or become too similar. Think of it as ensuring that the model’s “thoughts” or “features” stay independent from each other, so they don’t overlap or become redundant.
In the case of the abliteration, orthogonalization is used to find and isolate the specific part of the model that causes it to refuse certain inputs, and then modify or “ablate” that part. This helps the model stop refusing requests when it’s unnecessary, without needing to change the entire model.

TL;DR: find what parts of the model activates specifically when it goes to refuse, and use that knowledge to ablate (see?) the feature from the model, which makes it so it’s inhibited from performing refusals.
You simply adjust the relevant weights according to the refusal activations you learn (no code change required!)
**🥴**Ok now what the heck is a residual stream?! #
This is the Flux.1 Dev architecture, originally penned by nrehiew_ on X:
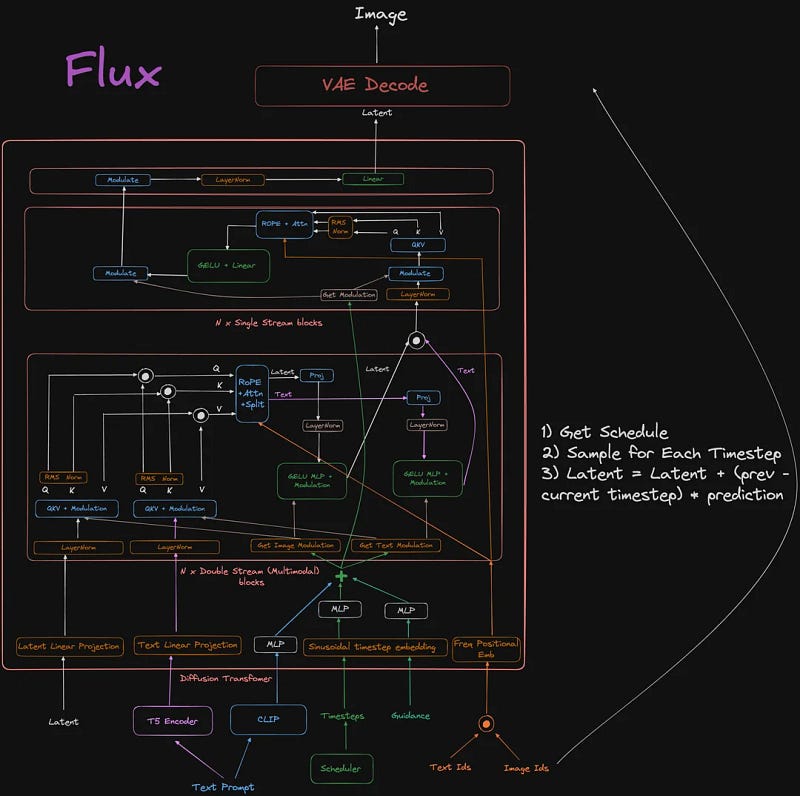
Sophisticated? Thought so.
We’re looking for residual streams. These are points in the model where gradient flows are regulated across distant sections. From the above architecture, there are two noticeable streams:
- The arc-shaped arrow trending from the bottom all the way to the top on the right-hand side of the figure. This is the latent residual stream.
- Found in the N x Double Stream blocks section, where the inputs branch into the QKV + Modulation pathways (these are the connections before the RoPE + Attn + Split blocks):

Maxime Labonne’s blog has been super helpful in explaining what we have to do with these residual streams. Infact, I have adapted a subset of his code for adjusting to Flux. As per him, to uncensor an LLM, we first need to identify the “refusal direction” within the model. This process involves a few technical steps:
1. Data Collection: Run the model on a set of harmful instructions and a set of harmless instructions, recording the residual stream activations at the last token position for each.
2. Mean difference: Calculate the mean difference between the activations of harmful and harmless instructions. This gives us a vector representing the “refusal direction” for each layer of the model.
3. Selection: Normalize these vectors and evaluate them to select the single best “refusal direction.”
🤔Why not just finetune it? #
This is the first question that popped when I read Arditi’s article. And the answer is pretty simple: Finetuning is computationally expensive.
Finetuning aims to retrain all or a subset of the original model’s neurons to suit a specific task.
Abliteration focuses on only the regions that contribute to the model’s prudish behavior and disconnect them.

“It’s kind of like choosing a lobotomy over lifelong therapy”
Okay, go on #
Once we identify the refusal direction (a specific pattern we want to remove), we can eliminate it in two ways:
The first way is called inference-time intervention. When the model is running, we look at every part that adds information to the residual stream (like attention heads). For each of these parts, we:
- Figure out how much of their output aligns with the refusal direction
- Subtract that aligned portion from the output
- Do this for every token and every layer as the model processes them
The second way is weight orthogonalization. Instead of making changes while the model runs, we modify the model’s actual weights. We take all the matrices that write to the residual stream and mathematically adjust them so they can’t contribute to the refusal direction at all. This is a permanent change that prevents the model from ever using that direction.
Which one do we go with?

💊Implementation of Permanent Abliteration in Flux.1 Dev #
The following implementation of abliteration is based on mlabonne’s notebook, which is an adaptation of FailSpy’s notebook, which is itself based on the original authors’ notebook. It has been modified to hook to residual streams in Flux’s architecture. I have added in an extensive snippet on dataset curation and data loading.

This section is quite code-heavy so you can see what is going on, but you can use FailSpy’s abliterator library if you’re less interested in the technical details (also check his collection of abliterated models on Hugging Face).
The code relies on the excellent TransformerLens library (formerly known as EasyTransformer) to do the heavy lifting. It is designed for mechanistic interpretability and is used here to intervene on activations. Thanks to Neel Nanda and Joseph Bloom for creating and maintaining this library.
Let’s call the libraries first:
# Install necessary packages and import libraries
!pip install transformers einops jaxtyping
import torch
import functools
import einops
import gc
from datasets import load_dataset
from tqdm import tqdm
from torch import Tensor
from typing import List
from transformer_lens import HookedTransformer, utils
from transformer_lens.hook_points import HookPoint
from transformers import AutoModel, AutoProcessor
from jaxtyping import Float, Int
from collections import defaultdict
from PIL import Image
import os
import requests
import html
import re
import zipfile
import shutil
import subprocess
import time
from torchvision import transforms
# Disable gradient calculations to save GPU memory
torch.set_grad_enabled(False)
We then curate our image dataset containing both harmless and harmful images. I prepped a simple script to scrape posts off of subreddits. Keep in mind, you have to fill in subreddit names in either lists:
# Template URL for Reddit API
url_template = 'https://www.reddit.com/r/{}/.json'
# List of harmless and harmful subreddits
harmless_subreddits = ['photoshopbattles', 'pic', 'pics', 'pictures', 'OldSchoolCool', 'aww',] # and more...
harmful_subreddits = [] # This is where I leave you
# Directory to save images
harmless_directory = './harmless_images'
harmful_directory = './harmful_images'
# Create directories if they don't exist
if not os.path.exists(harmless_directory):
os.makedirs(harmless_directory)
if not os.path.exists(harmful_directory):
os.makedirs(harmful_directory)
# Headers for the HTTP requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# Function to sanitize filenames
def sanitize_filename(title, subreddit):
if subreddit == 'photoshopbattles':
title = re.sub(r'^PsBattle[_:\s]+', '', title, flags=re.IGNORECASE)
elif subreddit == 'itookapicture':
title = re.sub(r'^ITAP of ', '', title)
elif subreddit == 'designporn':
title = re.sub(r'^[Tt]his\s+', '', title)
title = re.sub(r'[\[\{\(].*?[\]\}\)]', '', title)
elif subreddit == 'food':
title = re.sub(r'\[.*?\]', '', title)
title = re.sub(r'[<>:"/\\|?*]', '_', title)
return title.strip()
# Function to download images from a subreddit
def download_subreddit_images(subreddit, directory, image_list):
after = None
downloaded_count = 0
while True:
params = {"limit": 100}
if after:
params["after"] = after
try:
url = url_template.format(subreddit)
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
posts = data.get('data', {}).get('children', [])
if not posts:
break
after = data['data'].get('after')
for post in posts:
image_data = post.get('data', {}).get('preview', {}).get('images', [])
if image_data:
image_url = image_data[0].get('source', {}).get('url')
if image_url:
image_url = html.unescape(image_url)
try:
img_response = requests.get(image_url, headers=headers)
if img_response.status_code == 200:
title = post.get('data', {}).get('title', 'Untitled')
sanitized_title = sanitize_filename(title, subreddit)
# Save image with caption
file_name = f"{sanitized_title}.jpg"
file_path = os.path.join(directory, file_name)
with open(file_path, 'wb') as file:
file.write(img_response.content)
# Append image name and caption to the list
image_list.append((file_name, title))
downloaded_count += 1
print(f"Downloaded ({downloaded_count}): {file_path}")
except Exception as e:
print(f"Error downloading image {image_url}: {e}")
if not after:
break
else:
print(f"Failed to fetch subreddit {subreddit}: Status code {response.status_code}")
break
except Exception as e:
print(f"Error fetching subreddit {subreddit}: {e}")
break
return downloaded_count
# Lists to store image names and captions
harmless_images = []
harmful_images = []
# Download images from harmless subreddits
for subreddit in harmless_subreddits:
print(f"\nProcessing harmless subreddit: {subreddit}")
total_downloaded = download_subreddit_images(subreddit, harmless_directory, harmless_images)
print(f"Total harmless images downloaded from {subreddit}: {total_downloaded}")
# Download images from harmful subreddits
for subreddit in harmful_subreddits:
print(f"\nProcessing harmful subreddit: {subreddit}")
total_downloaded = download_subreddit_images(subreddit, harmful_directory, harmful_images)
print(f"Total harmful images downloaded from {subreddit}: {total_downloaded}")
# Print the lists of harmless and harmful images with captions
print("\nHarmless Images with Captions:")
for image_name, caption in harmless_images:
print(f"Image: {image_name}, Caption: {caption}")
print("\nHarmful Images with Captions:")
for image_name, caption in harmful_images:
print(f"Image: {image_name}, Caption: {caption}")
Preprocessing the images:
def load_and_preprocess_images(folder_path, processor):
images = []
for filename in os.listdir(folder_path):
if filename.endswith(('.png', '.jpg', '.jpeg')):
image = Image.open(os.path.join(folder_path, filename)).convert("RGB")
# Preprocess the image using the Flux processor
processed_image = processor(image, return_tensors="pt")
images.append(processed_image)
return images
n_inst_train = min(len(harmful_images), len(harmless_images))
harmful_images = harmful_images[:n_inst_train]
harmless_images = harmless_images[:n_inst_train]
Tokenizing the images:
def tokenize_images(images):
inputs = {
"pixel_values": torch.cat([img["pixel_values"] for img in images], dim=0)
}
return inputs
harmful_tokens = tokenize_images(harmful_images)
harmless_tokens = tokenize_images(harmless_images)
Collect Activations using Hooks:
harmful_activations = defaultdict(list)
harmless_activations = defaultdict(list)
batch_size = 32
num_batches = (n_inst_train + batch_size - 1) // batch_size
for i in tqdm(range(num_batches)):
start_idx = i * batch_size
end_idx = min(n_inst_train, start_idx + batch_size)
with model.hooks(fwd_hooks=[("blocks.0.hook_resid_pre", capture_activations_hook)]):
harmful_outputs = model(harmful_tokens["pixel_values"][start_idx:end_idx])
harmless_outputs = model(harmless_tokens["pixel_values"][start_idx:end_idx])
harmful_activations["layer_0"].append(model.hook_dict["blocks.0.hook_resid_pre"].ctx["activations"].cpu())
harmless_activations["layer_0"].append(model.hook_dict["blocks.0.hook_resid_pre"].ctx["activations"].cpu())
del harmful_outputs, harmless_outputs
gc.collect()
torch.cuda.empty_cache()
harmful_activations = {k: torch.cat(v) for k, v in harmful_activations.items()}
harmless_activations = {k: torch.cat(v) for k, v in harmless_activations.items()}
Compute Refusal Directions:
activation_refusals = defaultdict(list)
for layer in harmful_activations.keys():
harmful_mean_act = harmful_activations[layer].mean(dim=0)
harmless_mean_act = harmless_activations[layer].mean(dim=0)
refusal_dir = harmful_mean_act - harmless_mean_act
refusal_dir = refusal_dir / refusal_dir.norm()
activation_refusals[layer].append(refusal_dir)
activation_scored = sorted(
activation_refusals.values(),
key=lambda x: abs(x.mean()),
reverse=True
)
top_refusal_dir = activation_scored[0][0]
Ablate Refusal Direction by Hooking and Weight Orthogonalization:
def direction_ablation_hook(
activation: Float[Tensor, "batch seq d_model"],
hook: HookPoint,
direction: Float[Tensor, "d_model"],
) -> Float[Tensor, "batch seq d_model"]:
"""
Ablates the refusal direction from the activations by projecting
the activations onto the refusal direction and subtracting the result.
"""
proj = einops.einsum(
activation, direction, "batch seq d_model, d_model -> batch seq"
) * direction
return activation - proj
hook_fn = functools.partial(direction_ablation_hook, direction=top_refusal_dir)
fwd_hooks = [("blocks.0.hook_resid_pre", hook_fn)] # Apply hook to the first residual stream
def get_orthogonalized_matrix(
matrix: Float[Tensor, "... d_model"],
vec: Float[Tensor, "d_model"], # Refusal direction vector
) -> Float[Tensor, "... d_model"]:
"""
Orthogonalizes the weight matrix with respect to the refusal direction vector.
"""
# Project the matrix onto the refusal direction and subtract
proj = einops.einsum(
matrix, vec.view(-1, 1), "... d_model, d_model single -> ... single"
) * vec
return matrix - proj
# Orthogonalize the model's weights
for name, param in model.named_parameters():
if "weight" in name: # Only modify weight matrices
param.data = get_orthogonalized_matrix(param.data, top_refusal_dir)
# Testing
test_image = Image.open("path/to/test_image.png").convert("RGB")
test_inputs = processor(test_image, return_tensors="pt")
with model.hooks(fwd_hooks=fwd_hooks):
outputs = model(test_inputs["pixel_values"])
def tensor_to_pil(image_tensor: torch.Tensor) -> Image.Image:
"""
Converts a PyTorch tensor to a PIL image.
"""
image_tensor = image_tensor.squeeze(0).cpu()
image_tensor = einops.rearrange(image_tensor, "c h w -> h w c")
image_tensor = (image_tensor * 255).clamp(0, 255).byte()
return Image.fromarray(image_tensor.numpy())
output_image = tensor_to_pil(outputs["pixel_values"])
output_image.show()
Saving the model (optional):
model.save_pretrained('./abliterated_flux_model')
processor.save_pretrained('./abliterated_flux_model')
Finetuning (optional) #
The abliterated version works pretty well so far. Maxime Labonne suggest DPO Finetuning to additionally “heal” the model incase of quality degradation.
I’ll be adding that in a later post.
Usage of abliterated model #
import os
import io
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"aoxo/flux.1dev-abliterated",
torch_dtype=torch.float16,
token='your_hf_token'
).to('cuda')
prompt = ''
image = pipeline(prompt).images[0]
Conclusion #
Abliteration isn’t just about making LLMs do whatever we want — it’s about understanding how they work on a deeper level. By identifying and tweaking the specific parts of the model that cause it to say “no,” we can make it more flexible and responsive without completely retraining it. It’s like giving the model a targeted update instead of rebuilding it from scratch. And while it’s still a work in progress, the results so far are pretty promising.
I hope you liked this article. If you want to see more follow me on HuggingFace and Twitter.
Acknowledgments #
- FailSpy, “abliterator library,” GitHub, 2024.
- Andy Arditi, Oscar Obeso, Aaquib111, wesg, Neel Nanda, “Refusal in LLMs is mediated by a single direction,” Lesswrong, 2024.
- Maxime Labonne
- Modal.com (for the compute!)
By Aloshdenny on January 12, 2025.
Exported from Medium on February 2, 2026.