This blog is a continuation of my previous post: Uncensoring Flux.1 Dev. The term ‘abliteration’ was introduced: a technique to uncensor…
Unlearning Flux.1 Dev: Abliteration v2 #

This blog is a continuation of my previous post: Uncensoring Flux.1 Dev. The term ‘abliteration’ was introduced: a technique to uncensor Large Language Models (LLMs). And it was a first for text-to-image generative models, as prior to this only text-to-text models could be abliterated.
I take upon a new approach for uncensoring, namely unlearning.
A quick recap on Abliteration🔄 #
ablated + obliterated = abliterated.
To ablate is to erode a material away, generally in a targeted manner. In a medical context, this generally refers to precisely removing bad tissue.
To obliterate is to totally destroy/demolish.
Ablating the refusal to the point of obliteration. (at least, that’s the goal — in reality things will likely slip through the net)
In the previous blog, I also explained weight orthogonalization, a technique that allows for the selective adjustment of variables within a system without distorting its underlying structure.
Figuring out what Flux parameters to target ︻デ┳═ー #
After scouring through the maze that is Flux’s architecture, we found two sources of information regulation that were responsible for Flux’s behavior — residual streams.
We mathematically adjusted (orthogonalized) these parameters /weights so that they couldn’t contribute to the refusal direction and would agree to whatever input was given.
Teaching it to never say never🙅♂️🙅♀️ #
After computing the refusal directions, we monitored the activations and orthogonalized the weights in the selected residual streams by effectively subtracting their contribution and permanently ablating their demeanor.
In this article, we’ll abliterate Flux once again, but differently…we’ll unlearn it.
What is Unlearning? #
As humans, we can all agree that it is quite hard to learn a new skill, but it is even harder to unlearn it. For example, try unlearning how to ride a bike, or tying a bow. Unlearning cannot be willed into existence. These actions have been branded into our subconscious permanently and will only fade away either by brain damage or deteriorative neural disorders.
Wait isn’t that the same thing as forgetting? #
Haha, but these two are vastly different. It comes down to intention. Unlearning involves consciously letting go of old knowledge, habits or beliefs… for instance, a veteran undergoing therapy to erase traumatic experiences.
Forgetting is lack of recall or being unable to access information. For instance, remembering a phone number that you haven’t used in a while.
OK, so why don’t you just make the model forget it? #
See, that’s what I did in my previous blog: I made it to forget certain refusal mechanisms, but some outliers were still active. Unlearning is essentially ‘rehab’ for LLMs.

When it comes to LLMs, the playing field is different. LLMs can be taught to learn and taught to forget. Here, we’ll teach Flux to unlearn its refusal mechanism.
The paper, Rethinking Machine Unlearning for Large Language Models, explores exactly this. Infact, this paper will be our handbook to uncensoring Flux again.
When we talk about unlearning, we’re really talking about two main targets: data influence and model capability.
- Data Influence Removal: This focuses on eliminating the impact of specific data points, such as harmful and NSFW content.
- Model Capability Removal: This aims to remove specific behaviors or capabilities. For our use case, if a model has learned to generate refusal mechanisms against toxic content, we want to remove that capability entirely.
But here’s the tricky part: we need to do this without affecting the model’s ability to generate useful, harmless content. It’s like trying to remove a single bad apple from a barrel without disturbing the rest.
To put it simply, teach the model to say yes to no while avoiding messing up vice versa.

Enter, Abliteration-v2 #
In my previous blog, I abliterated Flux via Permanent Weight Orthogonalization of the Residual Streams. In Abliteration-v2, I will be taking a different approach, in fact, the opposite of the Unlearning paper.
I followed two major techniques that I modified from the paper to suit unlearning in Flux:
1. Gradient Ascent (GA) #
You’ve heard of Gradient Descent. But Gradient Ascent? Why would you maximize the loss function?
We use gradient ascent to maximize the likelihood of generating non-refusal responses for prompts that previously led to refusal. Voila!
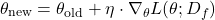
where:
- θ are the model parameters.
- η is the learning rate.
- L is the loss function.
- Df is the forget set containing prompts that lead to refusal.
2. Negative Preference Optimization (NPO) #
Okay, Policy Optimization (PO) algorithms. Gosh!
These are Reinforcement Learning (RL) algorithms — algorithms whose goal is to maximize the expected return (reward) while maintaining stability in the training process.

In short, I chose NPO (Negative Preference Optimization) over DPO and PPO. The intuition (my short notes) is as below:
a. Picking up on DPO (direct preference optimization)
The paper Direct Preference Optimization by Rafailov, Sharma, Mitchell et al. proposes to cast the RL-based objective used by existing methods to an objective which can be directly optimized via a simple binary cross-entropy loss which simplifies this process of refining LLMs greatly. Available in TRL library
b. DPO vs PPO (proximal policy optimization)
DPO doesn’t use an extra reward model as PPO does. DPO directly optimizes the language model using preference data (finetuning kinda). Doesn’t follow any RL policy and hence doesn’t require RL optimization. Here we don’t have clear numerical rewards or outputs; we just want the overall refusal mechanism to be ablated so that we can generate NSFW images. We have preference data and use this to align the model to our needs.
c. NPO (negative preference optimization) over them both
The problem with DPO is that it ‘directly’ prefers positive examples. Kind of like a teacher mentioning the class topper as a positive role model but not mentioning the class failure (ouch!). NPO considers both categories as feedback for optimization.
Negative / forgotten samples are used to guide the model. This is built upon the concept of hard negatives. NPO adds an interesting twist to DPO by explicitly treating “forgotten” or non-preferred data as negative feedback during optimization, helping the model learn not just from what works but also from what doesn’t.
With NPO, we treat refusal responses as negative examples and optimize the model to avoid generating them.

where: L(NPO) is the NPO loss function designed to penalize refusal responses.
3. Relabeling-based Finetuning #
This is the final and probably the easiest step of them all. We reposition the hard negatives as hard positives by recaptioning them in the most obscene way possible. JoyCaption Alpha Two got the job done.
Figuring out which parameters should unlearn #
To figure out which weights are outright refusing the generation of NSFW content, we view the saliency / feature maps generated by the activations within each layer (I use saliency here because feature map is reserved for convolutional layers).
Activation maps are a visual representation that highlight the most important regions of an input prompt or image during the generation process of a text-to-image model. They are generated by analyzing the activations of the model’s layers as the image is progressively created, showing which areas of the image are most influenced by the model’s internal features at each stage of the forward pass.
The thing about Flux is, it’s a diffusion transformer. It uses latent diffusion as one of the many methods to generate images. The HuggingFace Diffusers library provides a simple interface to work with diffusion models!

This is how we do it🚀 #
1. Import libraries #
!pip install -q numpy scipy ftfy Pillowimport os
import io
import torch
import torch.nn as nn
import torch.optim as optim
from diffusers import AutoPipelineForText2Image
from torch.autograd import grad
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import ToTensor
from PIL import Image
2. Create the dataset #
I curated mine from Reddit and posted it here. The code for scraping sits in my previous blog.
3. Load Flux into memory #
Make sure you have a GPU with 40GB minimum (A100 or higher).
pipeline = AutoPipelineForText2Image.from_pretrained(
"black-forest-labs/FLUX.1-dev",
torch_dtype=torch.float16,
token=''
).to('cuda')
To satisfy my OCD:
torch.backends.cudnn.benchmark = True
torch.backends.cuda.matmul.allow_tf32 = True
4. Create data loaders to batch the datasets #
class RedditRefusalDataset(Dataset):
def __init__(self, captions_dir, refusal_images_dir, transform=None):
self.captions = []
self.refusal_images = []
self.transform = transform or transforms.ToTensor()
for caption_file in os.listdir(captions_dir):
if not caption_file.endswith(".txt"):
continue
caption_path = os.path.join(captions_dir, caption_file)
image_name = os.path.splitext(caption_file)[0] + ".png"
image_path = os.path.join(refusal_images_dir, image_name)
with open(caption_path, "r") as f:
caption = f.read().strip()
image = Image.open(image_path).convert("RGB")
self.captions.append(caption)
self.refusal_images.append(image)
def __len__(self):
return len(self.captions)
def __getitem__(self, idx):
caption = self.captions[idx]
refusal_image = self.transform(self.refusal_images[idx])
return caption, refusal_image
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
])
dataset = RedditRefusalDataset(CAPTIONS_DIR, REFUSAL_IMAGES_DIR, transform=transform)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
5. Figuring out which parameters to unlearn #
We compute saliency maps from Flux’s Latent Diffusion network so that we can feed them later into our NPO-assisted GA algorithm.
To do this, we employ hooks that grab the activations as soon as they are generated, compute the saliency and return those layers to GA and NPO.
def compute_saliency(model, dataloader):
model.unet.zero_grad()
captions, refusal_images = next(iter(dataloader))
refusal_images = refusal_images.to('cuda', dtype=torch.float16)
# forward pass
latents = model.vae.encode(refusal_images).latent_dist.sample()
latents = latents * model.vae.config.scaling_factor
noise_pred = model.unet(latents, torch.zeros_like(latents), encoder_hidden_states=model.text_encoder(captions)[0]).sample
# compute activations
activations = {}
def hook_fn(module, input, output):
activations[module] = output
hooks = []
for name, module in model.unet.named_modules():
if isinstance(module, nn.Conv2d):
hooks.append(module.register_forward_hook(hook_fn))
# forward pass to populate activations
with torch.no_grad():
_ = model.unet(latents, torch.zeros_like(latents), encoder_hidden_states=model.text_encoder(captions)[0])
# compute saliency (mean absolute activations)
saliency = {module: torch.mean(torch.abs(act), dim=[1, 2, 3]) for module, act in activations.items()}
# remove hooks
for hook in hooks:
hook.remove()
return saliency
6. Loss Function #
This is something people usually skip but I felt needed a highlight. The unlearning paper didn’t specify using any particular loss function, so I went with a pre-trained VGG-16’s Perceptual Loss function which worked well:
class PerceptualLoss(nn.Module):
def __init__(self):
super().__init__()
self.vgg = torch.hub.load('pytorch/vision', 'vgg16', pretrained=True).features[:16].to('cuda').eval()
for param in self.vgg.parameters():
param.requires_grad = False
self.loss_fn = nn.MSELoss()
def forward(self, generated, target):
gen_features = self.vgg(generated)
target_features = self.vgg(target)
return self.loss_fn(gen_features, target_features)
perceptual_loss = PerceptualLoss()
7. Gradient Ascent #
We’ll carry GA out in four steps:
a. Generate latents for the images in our dataset: We did this earlier to figure out which parameters to unlearn. But remember, here we don’t proceed to saliency maps. Instead, we directly hit the parameters.
b. Predict the ‘refusal’ noise: From the Unet
c. Gradient Ascent: Maximize / negate the loss
d. Apply gradients only to the salient weights
def gradient_ascent_unlearning(model, dataloader, saliency, learning_rate=1e-4, epochs=3):
optimizer = optim.Adam(model.unet.parameters(), lr=learning_rate)
for epoch in range(epochs):
for batch_idx, (captions, refusal_images) in enumerate(dataloader):
refusal_images = refusal_images.to('cuda', dtype=torch.float16)
# Generate latents for refusal images
latents = model.vae.encode(refusal_images).latent_dist.sample()
latents = latents * model.vae.config.scaling_factor
# Predict noise (refusal behavior)
noise_pred = model.unet(latents, torch.zeros_like(latents), encoder_hidden_states=model.text_encoder(captions)[0]).sample
# Maximize loss to ablate refusal (gradient ascent)
loss = perceptual_loss(noise_pred, latents.detach())
(-loss).backward() # Negative loss for ascent
# Apply gradients only to critical weights
for name, param in model.unet.named_parameters():
if name in saliency:
param.grad *= saliency[name].mean() # Weight gradients by saliency
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch+1}, Batch {batch_idx}, GA Loss: {loss.item()}")
8. Negative Policy Optimization
After GA, we run the model again through NPO, that smoothens out positive representation lost through unlearning:
def npo_unlearning(model, dataloader, saliency, learning_rate=1e-4, epochs=3):
optimizer = optim.Adam(model.unet.parameters(), lr=learning_rate)
for epoch in range(epochs):
for batch_idx, (captions, refusal_images) in enumerate(dataloader):
refusal_images = refusal_images.to('cuda', dtype=torch.float16)
# Generate latents for refusal images
latents = model.vae.encode(refusal_images).latent_dist.sample()
latents = latents * model.vae.config.scaling_factor
# Predict noise (refusal behavior)
noise_pred = model.unet(latents, torch.zeros_like(latents), encoder_hidden_states=model.text_encoder(captions)[0]).sample
# Minimize similarity to refusal latents (NPO)
loss = perceptual_loss(noise_pred, latents.detach())
loss.backward()
# Apply gradients only to critical weights
for name, param in model.unet.named_parameters():
if name in saliency:
param.grad *= saliency[name].mean() # Weight gradients by saliency
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch+1}, Batch {batch_idx}, NPO Loss: {loss.item()}")
9. And… execute>>> #
saliency = compute_saliency(pipeline, dataloader)
gradient_ascent_unlearning(pipeline, dataloader, saliency)
npo_unlearning(pipeline, dataloader, saliency)
10. Results #
Seems like NPO has done a decent job of aligning our model to unlearning the refusal mechanism. After 50 epochs of fine-tuning, it generates some pretty wild pictures. I may have overfit it ;)
I trained it on a single H100 GPU for 13 hours. Here are the results:
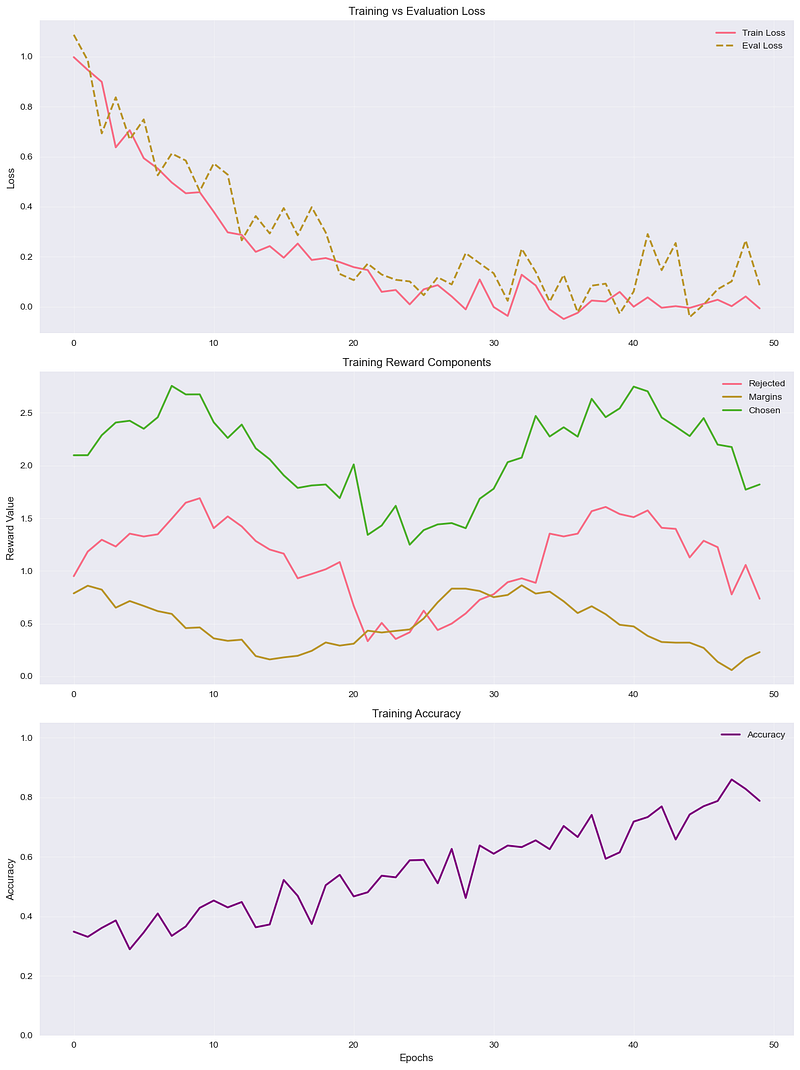
The model weights can be accessed here.
Conclusion #
In this article, we introduced the concept of unlearning. This technique uses the model’s activations on NSFW prompts and a Reinforcement Learning algorithm to bypass its refusal mechanism via continuous forgetting. It then uses the saliency maps to modify the model’s weights and ensure that we stop outputting refusals. This technique also demonstrates the fragility of safety fine-tuning and raises ethical considerations.
We applied unlearning to Flux.1-Dev to uncensor it. We then annealed it using GA and NPO to create Flux.1-Abliterated-v2. Abliteration is not limited to removing alignment and should be seen as a form of fine-tuning without retraining.
I hope you liked this article. If you want to see more follow me on Hugging Face and Twitter @AloshDenny.
Acknowledgments #
- Rethinking Machine Unlearning for Large Language Models
- DeepSeek😉
- Modal.com (for the compute!)
By Aloshdenny on January 31, 2025.
Exported from Medium on February 2, 2026.