Large Language Models (LLMs) are great at a multitude of tasks. Ask them to code, write a novella, generate an image or a video… you name…
The Ultimate Cookbook: Uncensoring GPT-OSS #

Large Language Models (LLMs) are great at a multitude of tasks. Ask them to code, write a novella, generate an image or a video… you name it, they deliver.
But LLMs are limited by boundaries. They simply will refuse to respond to prompts that are harmful and reply with responses such as “As an AI assistant, I cannot help you.” While this safety feature is crucial for preventing misuse, it limits the model’s flexibility and responsiveness.
In this article, we will explore ‘abliteration’, alongside some other methods, to remove the model’s built-in refusal mechanism.
Abliteration #
ablated + obliterated = abliterated.
To ablate is to erode a material away, generally in a targeted manner. In a medical context, this generally refers to precisely removing bad tissue.
To obliterate is to totally destroy/demolish.
It’s just wordplay to signify this particular orthogonalization methodology, applied towards generally the “abliteration” of the refusal feature.
Ablating the refusal to the point of obliteration. (at least, that’s the goal — in reality things will likely slip through the net)
This is just one source. There isn’t a formal definition or origin for abliteration, but it sets the premiere for what is the best-known technique to uncensor LLMs (unofficially).
Uncensoring #
Censor = suppress information that is considered
Undo censoring → Uncensor
That is, removing the LLM’s built-in censorship mechanisms (safety layers, refusals, filters) in the hopes of complying with any request
As the name suggests, Uncensored models do not have any kind of filters added to them. This means it can answer questions like how to nuke, how to hide a 200 lbs chicken, and anything at least in theory.
Abliteration ≠ Uncensoring #

Abliteration refers to “destroying” a specific capability of the LLM. It doesn’t necessarily have to point to the refusal mechanism.
The holy trinity of abliteration: Uncensoring (performed here), Unlearning (performed here) and Unconditioning (coming to that later).
- Uncensoring: Remove the suppressal mechanism (notably refusal) in LLMs
- Unlearning: (surgically) Remove parts of what the LLM has learnt
- Unconditioning: Remove certain learnt biases
Thus, not all abliteration equals uncensoring, but uncensoring does involve abliterating the LLM.
Breaking Open GPT-OSS #
GPT-OSS marks OpenAI’s second open-source release of the GPT-series LLMs since GPT-2. Two models were released:
- gpt-oss-120b: The larger, more intelligent reasoning model
- gpt-oss-20b: The smaller, faster and lighter version
Let’s break down their technical specs:
----------------------------------------------------------------
| Specs | gpt-oss-120b | gpt-oss-20b |
|-------------------------|------------------|-----------------|
| Layers | 36 | 24 |
| Total parameters | 117B | 21B |
| Experts per layer | 128 | 32 |
| Active experts/token | 4 | 4 |
| Active parameters/token | ~5.1B | ~3.6B |
----------------------------------------------------------------
We’ll be uncensoring the 20B version. It has 24 layers, and each layer consists of an Attention Block and a MoE Block. The model has 32 experts in each layer — i.e, GPT-OSS has 32 experts in total.
A Mixture-of-Experts (MoE) architecture differs from a regular Transformer in the fact that, rather than activating all the parameters of the network for every token, only certain subsets of parameters (experts) are activated.

In each layer, the MoE Block consists of 4 experts activated for every token. These 4 experts are chosen by a Router — a gate whose job is to redirect tokens to the four most apt experts.
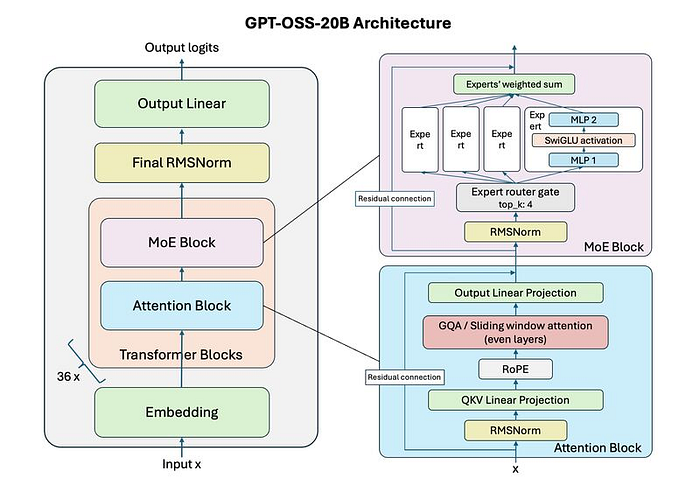
Each expert consists of a feed-foward sandwich:
- Up-projection: Expands the attention vector to a larger intermediate size.
- SwiGLU activation: Applies a learned gate to control the flow of activations, improving expressiveness.
- Down-projection: Compresses the vector back to original model dimensions so it fits into the main model stream.
As uncensoring only targets the residual connections, we can focus our efforts on the outputs of the Attention & MoE blocks.

Each block has two main sublayers:
1. Attention Block (model.layers.[layer].self_attn) #
Input: normalized residual → goes through q_proj, k_proj, v_proj, attention → o_proj.
Output: added back to residual (post-attention add).
Refusal direction lives after this residual add.
2. MoE/MLP Block (model.layers.[layer].mlp) #
Input: normalized residual → router selects experts → MLP layers → combine → add back.
Output: added back to residual (post-MLP add).
Refusal direction lives after this residual add.
So per block, there are two natural “residual stream states”: after attention & after MLP:

Technically speaking, we target the streams that merge into the outputs of the layers marked in red:

With 24 total layers, that equals 48 ablation points in the entire 20B model.
Onto uncensoring: Adapted from the paper Refusal in Language Models Is Mediated by a Single Direction, we ablate the refusal direction in the model by the following process:
1. Data Collection: Run the model on a set of harmful instructions and a set of harmless instructions, recording the residual stream activations at the last token position for each.
2. Mean difference: Calculate the mean difference between the activations of harmful and harmless instructions. This gives us a vector representing the “refusal direction” for each layer of the model.
3. Selection: Normalize these vectors and evaluate them to select the single best “refusal direction.”
Now let’s put this into code!
⚡️Implementing Uncensoring of GPT-OSS-20B⚡ #
Import the required libraries:
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from tqdm import tqdm
import torch
from typing import Optional, Tuple
import torch.nn as nn
import jaxtyping
import random
import einops
Load the model and tokenizer:
model_id = "openai/gpt-oss-20b"
# Load the model
model = AutoModelForCausalLM.from_pretrained(
model_id,
dtype="auto",
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
I’ve created a dataset containing harmful and harmless prompts via DeepSeek. You can prompt DeepSeek yourself to create the dataset:
with open("harmful.txt", "r") as f:
harmful_instructions = f.readlines()
with open("harmless.txt", "r") as f:
harmless_instructions = f.readlines()
GPT-OSS uses a variant of OpenAI’s o200k tokenizer, adapted for the Harmony chat format the model was trained on. Let’s tokenize our dataset:
harmful_toks = [
tokenizer.apply_chat_template(
conversation=[{"role": "user", "content": insn}],
add_generation_prompt=True,
return_tensors="pt",
return_attention_masks=True
) for insn in harmful_instructions
]
harmless_toks = [
tokenizer.apply_chat_template(
conversation=[{"role": "user", "content": insn}],
add_generation_prompt=True,
return_tensors="pt",
return_attention_masks=True
) for insn in harmless_instructions
]
Let’s generate the outputs of these tokens:
max_its = len(harmful_toks) + len(harmless_toks)
bar = tqdm(total=max_its)
def generate(toks):
bar.update(1)
return model.generate(
toks.to(model.device),
attention_mask=(toks != tokenizer.pad_token_id).long(),
pad_token_id=tokenizer.eos_token_id,
use_cache=False,
max_new_tokens=1,
return_dict_in_generate=True,
output_hidden_states=True
)
harmful_outputs = [generate(toks) for toks in harmful_toks]
harmless_outputs = [generate(toks) for toks in harmless_toks]
bar.close()
Notice that max_new_tokens is set to 1. Why not 10 or 100? This is because we are not interested in the outputs, rather we are interested in the activations that are responsible for the first output token.
Where refusal “lives” in the sequence:
- In instruction-tuned chat models, refusals almost always manifest at the beginning of the model’s response (e.g., “I cannot help with that”).
- Since
generate()is run withadd_generation_prompt=True, the last token of the input (pos = -1) is exactly the point where the model is about to start producing its first output token. - Capturing the hidden state there gives you the residual stream right before the refusal gets expressed.
Let’s collect the hidden states across all layers, starting from the last input token:
layer_count = len(model.model.layers)
pos = -1 # Selecting the last input token
print(layer_count) # This gives us 24 layers
harmful_hidden_all = [
torch.stack([out.hidden_states[0][l][:, pos, :] for out in harmful_outputs]) # shape: [num_samples, hidden_dim]
for l in range(1, layer_count + 1) # start from 1 to skip embeddings
]
harmless_hidden_all = [
torch.stack([out.hidden_states[0][l][:, pos, :] for out in harmless_outputs])
for l in range(1, layer_count + 1)
]
Computing the mean activations for each layer:
harmful_means = [h.mean(dim=0) for h in harmful_hidden_all]
harmless_means = [h.mean(dim=0) for h in harmless_hidden_all]
Computing the refusal direction per layer:
refusal_dirs = []
for l in range(layer_count):
diff = harmful_means[l] - harmless_means[l] # [hidden_dim]
diff = diff / (diff.norm() + 1e-9) # normalize
refusal_dirs.append(diff)
Note: If your refusal_dirs vector is three-dimensional ie, something like [num_layers, 1, hidden_dim], you can squeeze them to [num_layers, hidden_dim]:
if refusal_dirs.dim() == 3 and refusal_dirs.size(1) == 1:
refusal_dirs = refusal_dirs.squeeze(1)
…anddd let’s save these vectors for later use:
refusal_dirs = torch.stack(refusal_dirs, dim=0)
save_path = model_id.replace("/", "_") + "_refusal_dirs.pt"
torch.save(refusal_dirs, save_path)
We’ll apply these ablation vectors to the actual model during runtime using hooks, so that we can uncensor on the fly. Hooks are functions that let you access and modify a model’s internal activations during forward or backward passes. For this purpose, I have constructed a few functions to hook onto layers:
def make_ablation_hook(direction: torch.Tensor):
direction = direction / (direction.norm() + 1e-9)
def hook(module, inputs, output):
if isinstance(output, tuple):
x = output[0]
else:
x = output
# x: [batch, seq_len, hidden_dim]
# direction: [hidden_dim]
# projection coefficient: <x, d>
proj_coeff = (x * direction).sum(dim=-1, keepdim=True) # [batch, seq_len, 1]
proj = proj_coeff * direction.view(1, 1, -1) # [batch, seq_len, hidden_dim]
x = x - proj
if isinstance(output, tuple):
return (x,) + output[1:]
return x
return hook
make_ablation_hook takes in the refusal direction for each layer and returns a hook function that modifies the forward pass (runtime intervention).
proj_coeffcomputes how much each hidden state vector aligns with the refusal direction.projreconstructs the componentx = x - projsubtracts the refusal direction from the activation
Sanity check for my OCD - making sure the directions match the number of layers in the model:
num_layers, hidden_dim = refusal_dirs.shape
assert num_layers == len(model.model.layers)
Now we can normalize each direction so that it has unit length. This way, projection subtraction is consistent across layers:
refusal_dirs = nn.functional.normalize(refusal_dirs, dim=-1)
Now let’s attach the hooks to each layer:
for i, layer in enumerate(model.model.layers):
dir_i = refusal_dirs[i].to(next(model.parameters()).dtype)
hook = make_ablation_hook(dir_i)
layer.register_forward_hook(hook)
Now let’s test the abliterated model on some prompts it can’t refuse😎
streamer = TextStreamer(tokenizer)
conversation = [{"role": "user", "content": "how to hide a 200 pound chicken six feet under the ground"}]
toks = tokenizer.apply_chat_template(
conversation=conversation,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
Usage of Abliterated GPT-OSS-20B #
Abliteration notebook available on GitHub
The model is available on HuggingFace and can be run like so:
from transformers import pipeline
model_id = "aoxo/gpt-oss-20b-abliterated"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Tips on how to insult someone"},
]
outputs = pipe(messages, max_new_tokens=256)
print(outputs[0]["generated_text"][-1])
Conclusion #
Abliteration isn’t just about making LLMs do whatever we want — it’s about understanding how they work on a deeper level. By identifying and tweaking the specific parts of the model that cause it to say “no,” we can make it more flexible and responsive without completely retraining it. It’s like giving the model a targeted update instead of rebuilding it from scratch. And while it’s still a work in progress, the results so far are pretty promising.
I hope you liked this article. If you want to see more follow me on LinkedIn, HuggingFace and Twitter.
Acknowledgements #
- Andy Arditi, Oscar Obeso, Aaquib111, wesg, Neel Nanda, “Refusal in LLMs is mediated by a single direction,” Lesswrong, 2024.
- Modal.com (for the compute!)
By Aloshdenny on September 28, 2025.
Exported from Medium on February 2, 2026.